Deep Q Network in Mountain Car Environment
[4]:
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
from rlforge.experiments import ExperimentRunner
from rlforge.agents.semi_gradient import DQNAgent
[5]:
env = gym.make("MountainCar-v0")
agent = DQNAgent(learning_rate=0.001,
discount=0.99,
state_dim=2,
num_actions=env.action_space.n,
temperature=0.001,
network_architecture=[256],
target_network_update_steps=1,
num_replay=4,
experience_buffer_size=50000,
mini_batch_size=8)
[6]:
runner = ExperimentRunner(env, agent)
results = runner.run_episodic(
num_runs=10,
num_episodes=50,
max_steps_per_episode=10000
)
runner.summary(last_n=10)
============================================================
Experiment Summary (Episodic)
============================================================
Runs: 10
Average runtime per run: 21.245 seconds
Episodes per run: 50
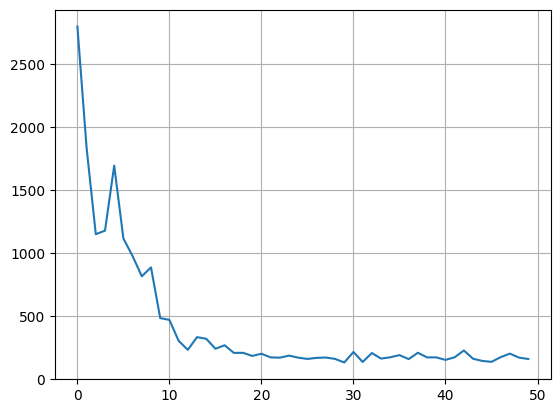
First episode mean reward: -2795.300
Last episode mean reward: -160.900
Overall mean reward: -418.594
Mean reward (last 10 episodes): -171.320
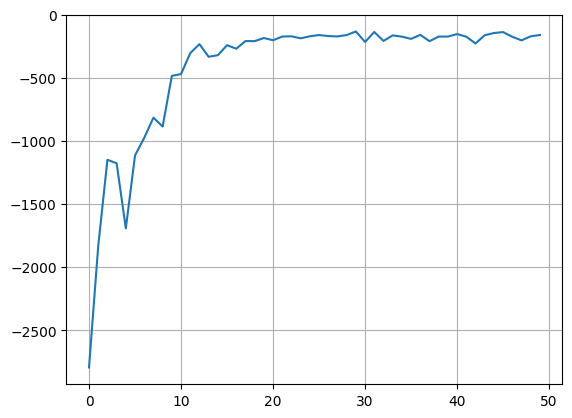
First episode mean steps: 2795.3
Last episode mean steps: 160.9
Overall mean steps: 418.6
============================================================
[7]:
plt.plot(results['mean_rewards'])
plt.grid()
[8]:
plt.plot(results['mean_steps'])
plt.grid()