Q-Learning Mecanum Car Environment
[1]:
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
from rlforge.experiments import ExperimentRunner
from rlforge.agents.semi_gradient import LinearQAgent
from rlforge.environments import MecanumCar
[2]:
env = MecanumCar(initial_state=(-0.5,0.5,0),
x_range=(-1,1),
y_range=(-1,1),
target=(0.5,-0.5,0.05),
dt=0.1)
agent = LinearQAgent(step_size=0.5/8,
discount=1,
num_actions=env.num_actions,
dims_ranges=((env.x_range[0],env.x_range[1]),(env.y_range[0],env.y_range[1]),(-np.pi,np.pi),(0,np.sqrt(32)),(-np.pi,np.pi)),
epsilon=0.1,
iht_size=4096,
num_tilings=8,
num_tiles=8,
wrap_dims=(False,False,True,False,True))
[3]:
runner = ExperimentRunner(env, agent)
results = runner.run_episodic(
num_runs=10,
num_episodes=500,
max_steps_per_episode=500
)
rewards = results["rewards"]
steps_per_episode = results["steps"]
runner.summary(last_n=10)
Run 1/10 - Episodes: 3%|▎ | 15/500 [00:00<00:17, 27.98it/s]
IHT full, starting to allow collisions
============================================================
Experiment Summary (Episodic)
============================================================
Runs: 10
Average runtime per run: 4.655 seconds
Episodes per run: 500
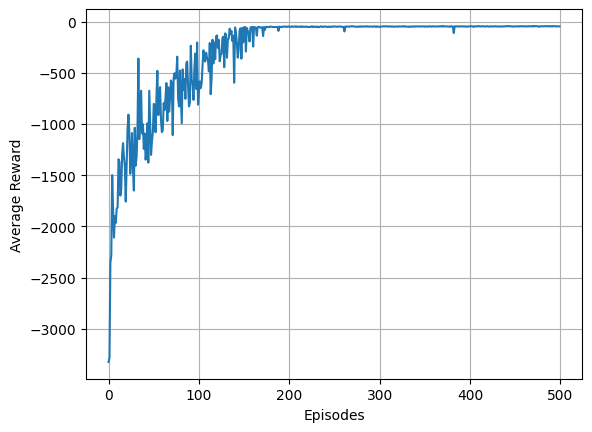
First episode mean reward: -3324.682
Last episode mean reward: -46.113
Overall mean reward: -275.024
Mean reward (last 10 episodes): -44.805
First episode mean steps: 467.8
Last episode mean steps: 49.8
Overall mean steps: 116.8
============================================================
[8]:
plt.plot(results['mean_rewards'])
plt.xlabel("Episodes")
plt.ylabel("Average Reward")
plt.grid()
[5]:
max_steps = 2000
rewards_test = []
steps = 0
states = []
actions = []
new_state = env.reset()[0]
states.append(new_state)
steps = 0
is_terminal = False
total_reward = 0
action = agent.start(new_state)
actions.append(action)
while not is_terminal:
new_state, reward, terminated, _, _ = env.step(action)
states.append(new_state)
is_terminal = terminated
if steps == max_steps - 1:
is_terminal = True
if is_terminal:
action = agent.end(reward)
else:
action = agent.step(reward, new_state)
actions.append(action)
rewards_test.append(reward)
steps += 1
[6]:
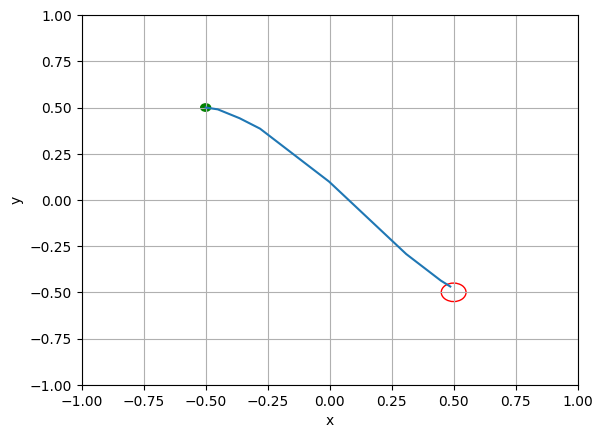
figure, axes = plt.subplots()
axes.set_ylim(env.y_range[0],env.y_range[1])
axes.set_xlim(env.x_range[0],env.x_range[1])
target = plt.Circle((env.target[0],env.target[1]), env.target[2], fill=False, color='r')
start = plt.Circle((env.initial_state[0],env.initial_state[1]), 0.02, color='g')
axes.add_artist(target)
axes.add_artist(start)
axes.plot(np.array(states)[:,0], np.array(states)[:,1])
axes.set_xlabel("x")
axes.set_ylabel("y")
plt.grid()
# plt.plot(np.array(states)[:,0], np.array(states)[:,1])
# plt.grid()
[7]:
plt.plot(rewards_test)
plt.grid()