SARSA Agent in Frozen Lake Environment
[6]:
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
from gymnasium.envs.toy_text.frozen_lake import generate_random_map
from rlforge.agents.tabular import SarsaAgent
from rlforge.experiments import ExperimentRunner
[7]:
env = gym.make("FrozenLake-v1",
is_slippery=False,
render_mode="rgb_array",
desc=generate_random_map(size=4, p=0.9))
agent = SarsaAgent(step_size=0.125,
discount=1,
num_states=env.observation_space.n,
num_actions=env.action_space.n,
epsilon=0.1)
[8]:
runner = ExperimentRunner(env, agent)
results = runner.run_episodic(
num_runs=100,
num_episodes=500,
max_steps_per_episode=10000
)
runner.summary()
============================================================
Experiment Summary (Episodic)
============================================================
Runs: 100
Total Runtime: 9.565 seconds
Average Runtime/Run: 0.096 seconds
------------------------------------------------------------
Episodes per run (Max): 500
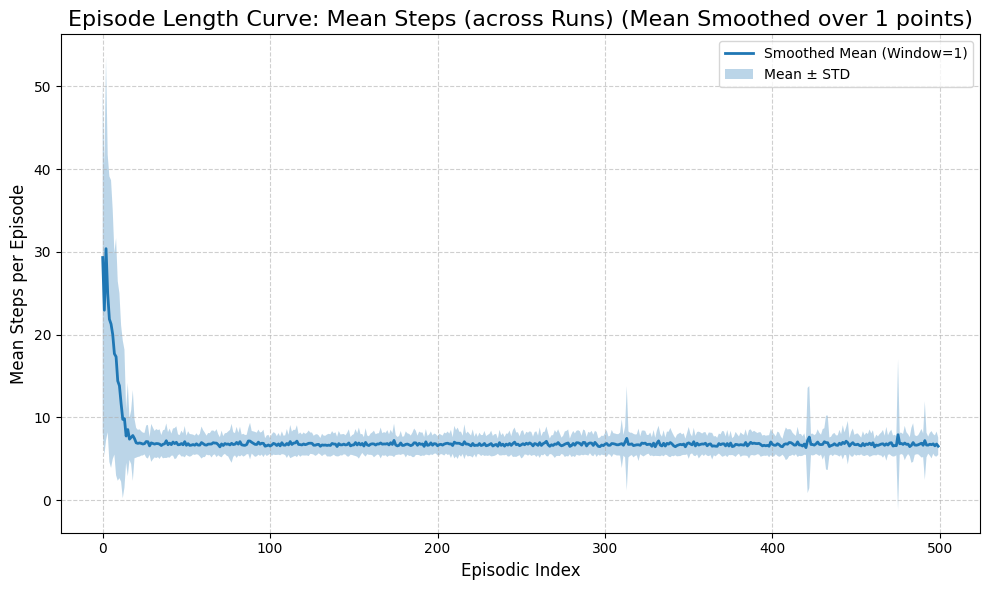
REWARDS
First Episode: 0.330 ± 0.470
Last Episode: 0.960 ± 0.196
Overall Mean: 0.973 ± 0.163
Last 10 Episodes: 0.974 ± 0.159
STEPS
First Episode: 29.3 ± 21.1
Last Episode: 6.5 ± 1.0
Overall Mean: 7.1 ± 3.8
============================================================
[9]:
runner.plot_results(window_size=1, max_reward=1)
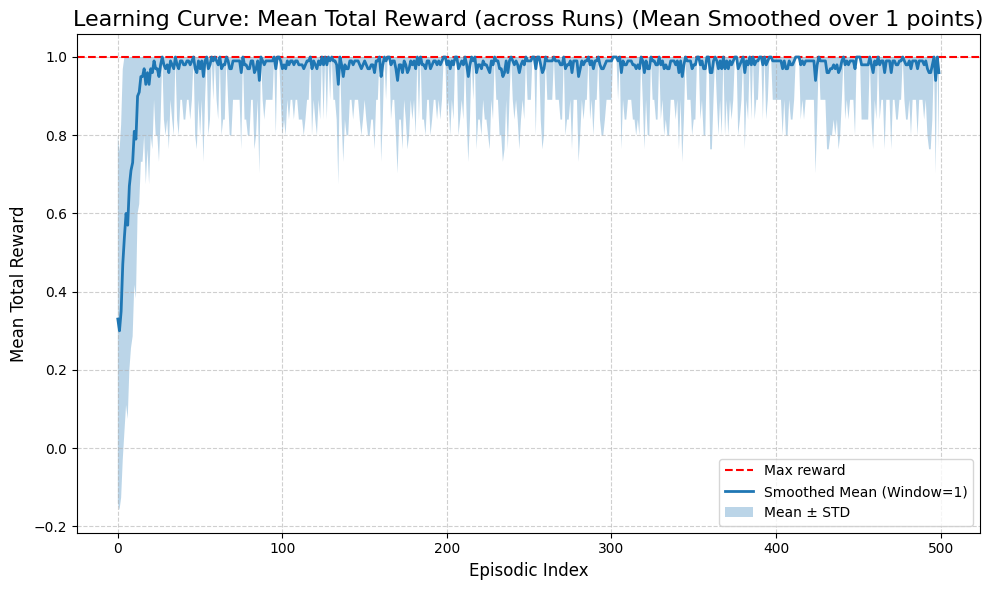
[10]:
runner.plot_results(metric='step', window_size=1)